OptiTech lanserar ny benchmark för att utvärdera konverserande RAG
Pressmeddelande 10 feb 2025
Ny benchmark för att utvärdera konverserande RAG
OptiTech har nu påbörjat utvecklingen av en ny dataset och benchmark för att utvärdera hur väl Large Language Model (LLM) presterar i interaktiva fråge- och svarsuppgifter med retrieval-augmented generation (RAG).

En ny standard för att utvärdera RAG i konversationer
Retrieval-augmented generation (RAG), har blivit en populär metod för att använda AI för att snabbt hitta pålitliga och verifierbara svar på frågor. Genom en RAG-pipeline kan språkmodeller hämta information från databaser eller andra externa källor för att basera sina svar på den senaste, mest relevanta informationen, utan att behöva träna om modellen.
RAG hjälper till att förhindra att LLM:er improviserar när de saknar svar, vilket minskar risken för felaktig eller fabricerad information. Som ytterligare en säkerhetsåtgärd gör RAG det möjligt för användare att kontrollera källor och verifiera att informationen är korrekt. Idag är LLM:er mycket skickliga på enskilda fråge- och svarsuppgifter, men när en uppgift blir mer komplex och kräver en interaktiv konversation likt en dialog med en människa, sjunker prestandan.
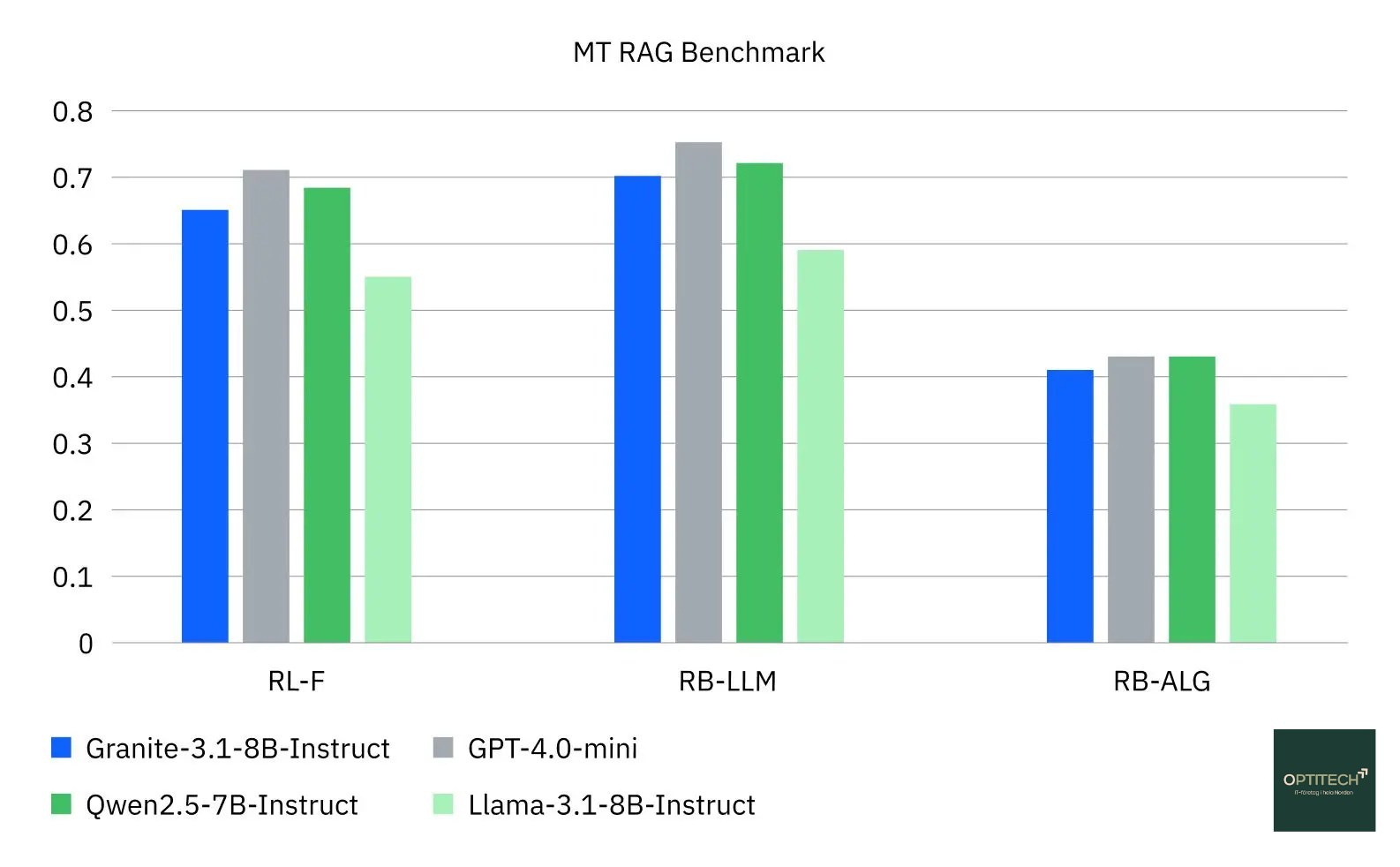
OptiTechs nya benchmark och dataset är utformade för att utvärdera LLM:er för den osäkerhet och oförutsägbarhet som präglar en livechatt med en riktig person. Datasetet innehåller 110 förlängda konversationer inom fyra affärsrelevanta områden: finans, allmän kunskap, IT-dokumentation och offentlig förvaltning.

Utvärdering av RAG i interaktiva scenarier
Många av frågorna i datasetet är avsiktligt formulerade för att vara delvis eller helt obesvarbara. Syftet är att undersöka om agenten skulle improvisera när den borde be om förtydligande eller helt enkelt svara ”Jag vet inte”.
OptiTechs dataset har utformats för att efterlikna naturliga samtal. Forskare och annotatörer interagerade med en live RAG-agent via en anpassad chattapplikation, Conversational Workbench, där de utvärderade både de hämtade informationen och kvaliteten på LLM:ens sammanfattade svar.
Retrieval-augmented generation (RAG) i framtiden
Vissa menar att utvecklingen av språkmodeller med större kontextfönster kan eliminera behovet av RAG. Istället för att använda en RAG-process för att hämta och sammanfatta data, kan man mata in all relevant information direkt i modellens kontextfönster.
Andra anser att RAG fortfarande kommer att vara relevant under lång tid framöver. LLM:er upplever informationsöverbelastning när för mycket data pressas in i deras kontextfönster, vilket kan försämra prestandan. RAG är också fortfarande det bästa sättet att söka i enorma databaser eller sammanställa motsägelsefull information för att generera mer exakta svar.
Nästa steg
OptiTech planerar att vidareutveckla datasetet genom att införa meningsbaserade citat, så att användare snabbare kan kontrollera om ett AI-genererat svar är korrekt. Dessutom kommer datasetet att utvidgas med fler områden av kunskap för att ytterligare förbättra träningen av framtida AI-modeller.
”Detta initiativ är skapat för att simulera verkliga samtal, och vi hoppas att det kommer att göra OptiTechs AI-modeller ännu mer användbara för våra kunder,” säger Adam Hill på OptiTech.
För mer information– kontakta:
Yazan Ghayad, Chief Executive Officer – OptiTech Sverige, yazanghayad@optitech-sverige.se