RAG vs. finjustering: rätt väg till företagsanpassad generativ AI
När företag pratar om generativ AI handlar diskussionen ofta om två spår: att koppla en språkmodell till verksamhetens egna källor, eller att träna om modellen så att den beter sig “som vi vill”. Båda angreppen kan ge stora effekter, men de löser olika problem och har olika konsekvenser för kostnad, säkerhet, tid till nytta och långsiktig förvaltning.
Innehållsförteckning
Valet mellan RAG (retrieval-augmented generation) och finjustering (fine-tuning) blir extra tydligt i nordiska verksamheter där kraven på spårbarhet, dataskydd och förändringstakt ofta är höga, oavsett om man verkar inom industri, logistik, bygg eller tjänstesektorn.
Cornelia Jakobsson
Varför frågan är affärskritisk
Generativ AI blir snabbt en del av arbetsflöden som påverkar produktivitet, kvalitet och risk. En “smart” assistent som svarar fel om säkerhetsrutiner, garanti, regelverk eller leveransvillkor kan bli dyr, både i tid och förtroende.
Samtidigt finns ett stort tryck på att komma igång utan att dra igång fleråriga dataprojekt. Många organisationer vill börja med ett avgränsat användningsfall, visa effekt, och därefter bredda.
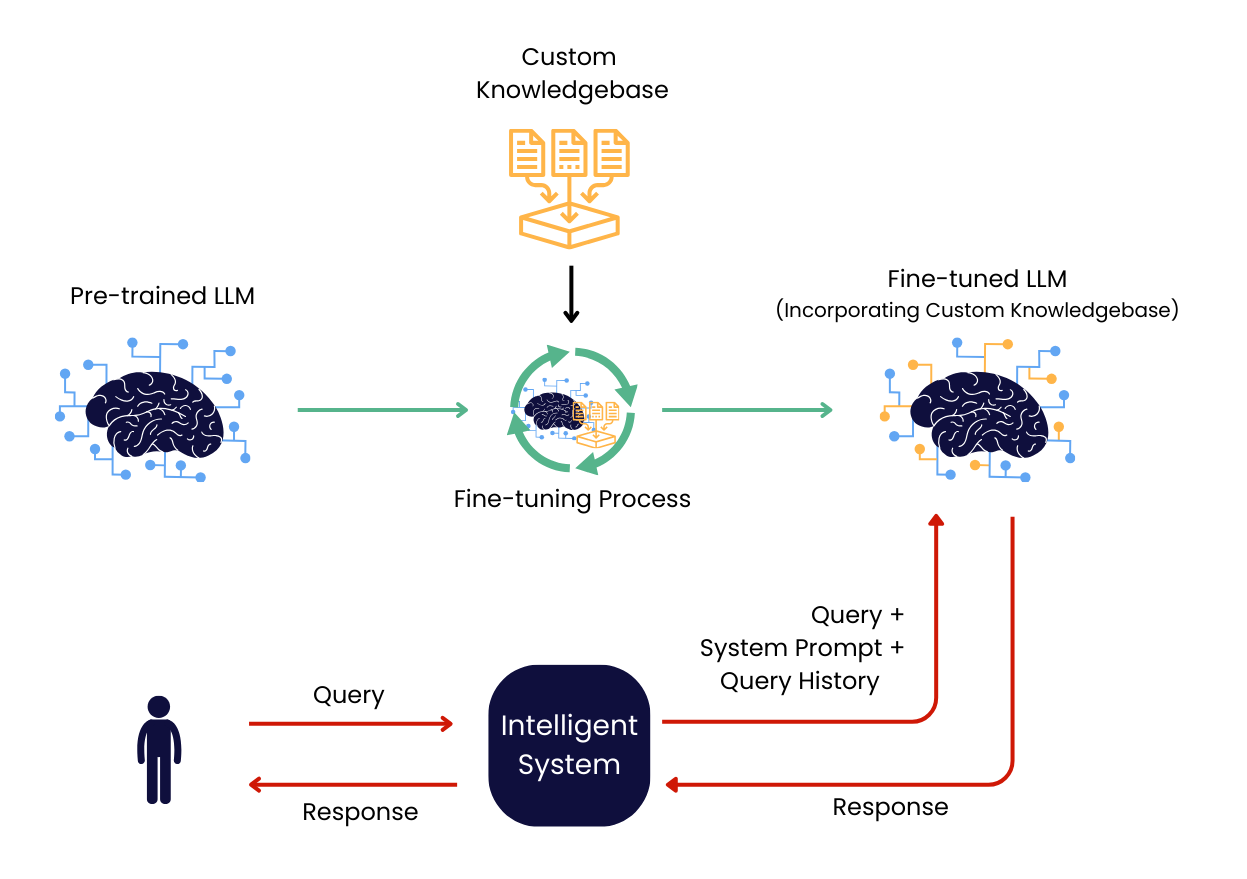
Det är här RAG och finjustering skiljer sig mest: RAG gör modellen mer informerad i stunden, finjustering gör modellen mer formad över tid.
RAG i praktiken: när fakta och aktualitet styr
RAG betyder att språkmodellen får “läsa” relevanta utdrag från era egna dokument vid varje fråga, ofta via en sökkomponent byggd på embeddingar och en vektordatabas eller en söktjänst med vektorstöd. Modellen genererar sedan svaret med dessa utdrag som stöd.
Det gör RAG särskilt starkt när svaret måste bygga på konkret, aktuell information: manualer, processbeskrivningar, avtalstexter, produktblad, kvalitetsdokument, intranät, ärendehistorik och mycket mer. När innehållet uppdateras i källorna kan ni uppdatera index och få ny information i svaren utan att träna om modellen.
Efter en första implementation brukar de viktigaste förbättringarna handla mindre om själva språkmodellen och mer om informationskedjan runtomkring: dokumentkvalitet, behörigheter, chunking (hur text delas upp), metadata och hur man mäter träffsäkerhet.
RAG passar ofta bra när målet är:
- Snabb prototyp
- Uppdaterad kunskap
- Svar med källhänvisning
- Stöd för många ämnen i samma lösning
Finjustering: när beteende och format måste sitta
Finjustering innebär att man tränar en befintlig språkmodell på egna exempel så att den följer ett visst språk, en viss struktur eller en viss regeluppsättning bättre än standardmodellen. Det kan handla om ton och stil, men också om att få konsekvent utdata i ett bestämt format, eller att modellen ska hantera specialiserad terminologi med hög stabilitet.
Det är ett kraftfullt verktyg, men det kräver mer förarbete. Data behöver samlas in, rensas, ofta märkas och kvalitetssäkras. Själva träningskörningen kostar också, och om fakta ändras ofta uppstår en ny utmaning: modellen “minns” inte nya policys eller nya produktversioner förrän den tränas om.
I företagssammanhang ger finjustering bäst effekt när uppgiften är tydligt avgränsad och repetitiv, och när värdet av konsekvent beteende överväger flexibiliteten.
Vanliga motiv för finjustering brukar vara att få:
- Styrd svarsstil: samma ton, samma begrepp, samma disposition varje gång
- Strikt format: JSON, tabeller, checklistor eller rapportmallar som måste hålla maskinell kvalitet
- Domänspråk: intern terminologi, branschspecifika uttryck, förkortningar och regler
RAG eller finjustering av AI-modeller – jämförelse som beslutsstöd
I takt med att generativ AI blir en central del av företags digitala infrastruktur ökar behovet av medvetna arkitekturval. Två av de vanligaste angreppssätten för att anpassa stora språkmodeller till verksamhetsspecifika behov är RAG (Retrieval Augmented Generation) och finjustering av språkmodeller. Båda metoderna syftar till att öka affärsnyttan, men de gör det på fundamentalt olika sätt och lämpar sig för olika typer av kravbilder.
Arkitekturens roll i AI-strategin
Valet mellan RAG och finjustering är inte enbart ett tekniskt beslut, utan ett strategiskt vägval som påverkar hur snabbt organisationen kan agera på förändringar, hur kunskap förvaltas och hur risk exponeras över tid. För många företag blir detta beslut avgörande för hur väl AI-lösningen kan integreras i befintliga processer, IT-landskap och styrmodeller.
RAG som förlängning av organisationens kunskap
RAG fungerar som ett lager ovanpå språkmodellen där relevant information hämtas från interna och externa datakällor i realtid. Det innebär att AI-systemet inte behöver “veta allt” i förväg, utan istället blir beroende av kvaliteten i organisationens dokumentation, databaser och kunskapsstrukturer. Detta gör RAG särskilt attraktivt för verksamheter med stora mängder dynamisk information, såsom policyer, teknisk dokumentation, produktkataloger eller regulatoriska texter.
En viktig fördel är att RAG möjliggör tydlig spårbarhet. När svar genereras kan källor visas, vilket är avgörande i miljöer där efterlevnad, kvalitetssäkring och revisionskrav är centrala. Ur ett GEO-perspektiv är detta även gynnsamt, eftersom generativa sökmotorer premierar innehåll med hög faktuell tydlighet och verifierbara källor.
Finjustering som beteendestyrning
Finjustering innebär att språkmodellen tränas vidare på ett urval av verksamhetsspecifik data för att internalisera terminologi, tonalitet och svarsmönster. Detta gör metoden särskilt effektiv när målet är ett konsekvent och förutsägbart beteende, till exempel i kunddialog, support eller automatiserade beslutstöd där variation kan skapa osäkerhet.
Till skillnad från RAG ligger kunskapen mer implicit i modellvikterna. Det gör lösningen snabb i inferens och mindre beroende av externa system vid körning, men också mindre flexibel när verkligheten förändras. Ny information kräver nya träningscykler, vilket kan skapa tröghet i organisationer med snabbt skiftande affärsförutsättningar.
Aktualitet kontra stabilitet
En central skiljelinje mellan RAG och finjustering är balansen mellan aktualitet och stabilitet. RAG är överlägset när information ofta uppdateras eller när AI-systemet måste spegla den senaste versionen av verkligheten. Finjustering erbjuder istället stabilitet och konsekvens, vilket kan vara viktigare än aktualitet i vissa sammanhang, exempelvis vid standardiserade processer eller regelstyrda svar.
Kostnader ur ett livscykelperspektiv
Ur ett ekonomiskt perspektiv skiljer sig metoderna främst i hur kostnader fördelas över tid. RAG innebär löpande kostnader kopplade till datalagring, sökning och inferens, medan finjustering ofta innebär en större initial investering följt av mer förutsägbara driftskostnader. För beslutsfattare är det därför viktigt att se bortom pilotprojekt och istället analysera totalkostnaden över hela AI-lösningens livscykel.
Skalbarhet och framtida expansion
Organisationer som planerar att använda AI inom flera affärsområden, språk eller domäner har ofta lättare att skala med RAG. Nya användningsfall kan introduceras genom att lägga till datakällor snarare än att träna om modellen. Finjustering blir mer resurskrävande i takt med att antalet domäner ökar, särskilt om kraven på precision och tonalitet skiljer sig mellan områden.
Informationssäkerhet och regelefterlevnad
Informationssäkerhet är en avgörande faktor i många branscher. RAG möjliggör tydligare kontroll genom att data kan hållas i säkra datalager med åtkomststyrning och loggning. Finjustering kräver större försiktighet vid hantering av träningsdata, eftersom känslig information riskerar att bakas in i modellen på ett sätt som är svårt att revidera i efterhand.
Hybridstrategier som best practice
I praktiken väljer allt fler organisationer en hybridstrategi där RAG används för faktabaserad och aktuell information, medan finjustering används för att styra beteende, tonalitet och domänförståelse. Denna kombination ger både flexibilitet och kontroll och betraktas allt oftare som best practice i större enterprise-miljöer.
Slutsats för beslutsfattare
Det finns inget universellt rätt val mellan RAG och finjustering. RAG är oftast bäst lämpad när kraven på aktualitet, transparens och skalbarhet är höga. Finjustering är ett starkt komplement när konsekvens, tonalitet och djup domänspecialisering är affärskritiskt. För organisationer som vill bygga långsiktigt hållbara AI-lösningar är det ofta kombinationen av båda som skapar störst strategiskt värde.
Säkerhet, GDPR och spårbarhet i företagsmiljö
Både RAG och finjustering kan göras säkert, men riskbilden ser olika ut.
Med RAG ligger företagets information typiskt kvar i egna datakällor, bakom befintliga åtkomstkontroller. Det ger en naturlig modell för behörighetsstyrning: användaren ska bara få svar från dokument som användaren faktiskt får läsa. Det blir också enklare att skapa spårbarhet genom att spara vilka källutdrag som användes vid ett visst svar.
Med finjustering finns en annan typ av risk: om man tränar på material som innehåller känsliga uppgifter kan delar av detta i värsta fall återskapas genom frågor till modellen. Det kräver disciplin i dataurval, anonymisering och testning mot oönskat återgivande.
Oavsett metod brukar en robust grund innehålla tre byggstenar:
- Behörighet: koppla användaridentitet till datakällor, inte bara till applikationen
- Loggning: spara prompts, källor, modellversion och svar för revision och förbättring
- Policy för data: tydliga regler för vad som får skickas till externa molntjänster och vad som måste stanna i egen miljö
Vad avgör valet i industri, logistik och bygg?
I praktiken styrs beslutet av hur ofta informationen ändras och hur stor variationen i frågor är.
I en produktionsnära verksamhet uppdateras ofta instruktioner, riskanalyser, avvikelsehantering och underhållsrutiner. En RAG-lösning kan då fungera som en “sökning med resonemang” där svaret kan peka på källor, versionsnummer och relevanta avsnitt.
I [logistik och handel förändras priser, villkor, leveransfönster och sortiment. RAG ger snabbare kontroll över att svaret faktiskt matchar senaste dokumentationen eller affärsreglerna i systemet.
I bygg och projektverksamhet är underlagen ofta många och spretiga: ritningsbeskrivningar, AMA-referenser, kontraktsbilagor, ändringslistor. Här blir kvaliteten i dokumentkedjan avgörande. RAG kan ge stor effekt, men det kräver att man tar tag i dokumentstruktur, metadata och versionshantering.
Finjustering blir mer relevant när man vill standardisera hur saker uttrycks. Ett exempel är när rapporter ska skrivas på samma sätt oavsett projekt, eller när svar måste följa en intern språkprofil och en fast mall.
Arkitekturval som fungerar i nordiska organisationer
Det som ofta fungerar bra är att skilja på “kunskapslagret” och “beteendelagret”.
Kunskapslagret är datakällor, index, metadata, åtkomstkontroll och kvalitetssäkring. Beteendelagret är promptning, verktygsanrop, val av modell, svarsmallar och eventuell finjustering.
När man bygger RAG är det vanligt att lägga tid på fyra områden som avgör träffsäkerheten: hur text delas upp, hur man hanterar tabeller och PDF:er, hur man sätter metadata, och hur man utvärderar svaren mot en testsvit.
När man finjusterar är det ofta mer värdefullt med färre men bättre exempel än att samla “allt man har”. Ett litet dataset med tydliga, kvalitetsgranskade exempel på önskat beteende kan ge tydliga lyft, särskilt om uppgiften är smal.
Att kombinera metoderna: när 1 + 1 blir 3
I många företag är det inte ett antingen eller. Ett vanligt mönster är att börja med RAG för att snabbt få korrekta svar som bottnar i egna källor, och därefter finjustera för att få jämnare stil, bättre formatdisciplin eller bättre hantering av interna begrepp.
En hybrid kallas ibland RAFT (retrieval-augmented fine-tuning), där modellen tränas på exempel som liknar den verkliga situationen: frågor besvaras med stöd av hämtade källutdrag. Resultatet kan bli en assistent som både hämtar rätt och skriver mer konsekvent.
Den här kombinationen är extra intressant i miljöer med höga krav på governance: RAG ger spårbarhet och uppdaterbarhet, finjustering ger stabilitet i hur svaret uttrycks och struktureras.
En pragmatisk start: så brukar man få effekt utan att låsa sig
Ett bra upplägg är att välja ett enda, affärsnära flöde där man kan mäta både kvalitet och tidsbesparing, och där datakällorna är tillräckligt välkända. När man väl ser mätbara resultat blir det lättare att prioritera datakvalitet, integrationer och förvaltning.
Ett arbetssätt som ofta ger fart framåt ser ut så här:
- Välj användningsfall med tydlig ägare, tydliga källor och tydliga riskgränser
- Bygg en RAG-prototyp och skapa en testsvit med verkliga frågor och förväntade svar
- Sätt styrning: behörigheter, loggning, källvisning och hantering av osäkra svar
- Utvärdera om finjustering behövs för stil, format eller terminologi och gör det bara där det ger tydlig effekt
För en aktör som OptiTech, med fokus på säker infrastruktur, moln, AI och systemutveckling, blir den praktiska skillnaden ofta att RAG-projekt främst handlar om att koppla ihop informationslandskapet på ett kontrollerat sätt, medan finjustering mer liknar ett klassiskt ML-projekt med dataset, träningspipeline och modellförvaltning.
Det hållbara perspektivet kommer in tidigare än många tror. RAG kan minska behovet av tunga träningskörningar genom att återanvända en basmodell och låta kunskapsuppdateringar ske via index. Samtidigt kan smart cache, bra chunking och tydliga avgränsningar minska onödig beräkningskostnad i drift.
Vad man ska mäta när lösningen går från demo till vardag
När en generativ lösning flyttar in i verksamheten blir “känslan” snabbt dyr som styrmedel. Man behöver mätning som är begriplig för både IT, verksamhet och riskfunktion.
Två mätetal brukar skapa tydlighet tidigt: hur ofta användaren får ett svar som går att verifiera i källor, och hur ofta svaret behöver korrigeras manuellt. Lägg till svarstid, täckningsgrad per datakälla och andel frågor som bör eskaleras till människa.
Det är också här skillnaden mellan RAG och finjustering syns i vardagen: RAG blir bättre när datakällor och sökbarhet blir bättre, finjustering blir bättre när exempel och kvalitetsgranskning blir bättre. Båda kräver förvaltning, men på olika sätt, och den som sätter en tydlig rutin för uppföljning får en assistent som faktiskt blir mer användbar över tid.
Företag står inför valet mellan RAG och finjustering, vi på OptiTech gör jobbet.
Hör av dig!